New Story
The ABCs of Microservices: A Simple Introduction
by dejanualexMarch 7th, 2025





Too Long; Didn't Read
Distributed systems are built for size and resilience, but distributing state across services means that every call to an external service is more or less an availability dice roll. Microservices are a way to drive profits not to reduce costs. One can use microservices to reach more customers and develop features in parallel.Companies Mentioned






We’re working in distributed teams, projects, and we even distribute compute resources in Regions and Zones (for cloud-based environments).
Generally speaking, a distributed system is nothing more than a system whose components are spread across multiple computers in a network to split up the work and coordinate their efforts to complete the job more efficiently than if a single machine had been responsible for it.
Distributed System
Microservices are self-contained and “independent” services decoupled from each other that can communicate between them via:
- Brokers
- RPC
- REST
The truth is that most often cross-dependencies are implied since no service can perform without getting help from other services. From a simplified perspective, the transition from a single-process monolith to microservices boils down to switching from function calls to network calls (gRPC/RPC, REST API).


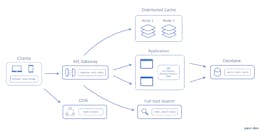
Microservices Recipe
For a simple classical microservice architecture we need:
- Multiple Independent Services — each service is responsible for a specific functionality;
- API Gateway — single entry point for clients, used to handle authentication, request routing, and load balancing;
- Database per Service — each service has its own database to ensure loose coupling, being the next step from SOA (Service Oriented Architecture) by addressing shortcomings like Enterprise Service Bus (ESB) and single shared database.
Distributed Monolith
Sometimes the implementation of microservices can lead to a distributed monolith. A distributed monolith fails to deliver on the promises of microservices, and it has all the disadvantages of a distributed system and as well the disadvantages of a monolith.
So even if the system consists of multiple services, but for some reason, the entire system must be deployed together, then you have on your hands a distributed monolith.


There’s No Such Thing as a Free Lunch
Distributed systems are indeed built for size and resilience, but distributing state across services means that every call to an external service is more or less an availability dice roll…
From a Business Perspective
Microservices are a way to drive profits not to reduce costs (are not meant for a cost-cutting architecture approach), one can use microservices to reach more customers and develop features in parallel.

L O A D I N G
. . . comments & more!
. . . comments & more!