





















































Jan 01, 1970
Python-ի հիմնական գիտելիքները կարող են օգնել ձեզ կառուցել ձեր սեփական մեքենայական ուսուցման մոդելը կողմից@buzzpy
27,623 ընթերցումներ
Python-ի հիմնական գիտելիքները կարող են օգնել ձեզ կառուցել ձեր սեփական մեքենայական ուսուցման մոդելը
Չափազանց երկար; Կարդալ
Եկեք կառուցենք մեր սեփական մեքենայական ուսուցման մոդելը Tensorflow-ի միջոցով, որը Python գրադարանն է:
Բարև գեղեցիկ մարդիկ: Հուսով եմ, որ 2025 թվականը ձեզ լավ է վերաբերվում, թեև մինչ այժմ դա ինձ համար դժվար էր:
Բարի գալուստ Doodles and Programming բլոգ, և այսօր մենք պատրաստվում ենք ստեղծել՝ TensorFlow + Python-ի միջոցով տրամադրությունների վերլուծության մոդել:
Այս ձեռնարկում մենք նաև կիմանանք Python-ով մեքենայական ուսուցման հիմունքների մասին, և ինչպես նախկինում նշվեց, մենք կկարողանանք կառուցել մեր սեփական մեքենայական ուսուցման մոդելը Tensorflow-ի միջոցով՝ Python գրադարան: Այս մոդելը կկարողանա հայտնաբերել մուտքագրված տեքստի տոնայնությունը/զգացմունքը ՝ ուսումնասիրելով և սովորելով տրամադրված տվյալների հավաքածուից:
Նախադրյալներ
Մեզ միայն անհրաժեշտ է Python-ի որոշակի իմացություն (ամենատարրական բաները, իհարկե), ինչպես նաև համոզվեք, որ ձեր համակարգում տեղադրված եք Python (խորհուրդ է տրվում Python 3.9+):
Այնուամենայնիվ, եթե ձեզ համար դժվար է անցնել այս ձեռնարկը, մի անհանգստացեք: Նկարեք ինձ էլփոստ կամ հաղորդագրություն; Ես կվերադառնամ ձեզ ASAP.
Եթե դուք տեղյակ չեք, ի՞նչ է մեքենայական ուսուցումը:
Պարզ ասած, մեքենայական ուսուցումը (ML) ստիպում է համակարգչին սովորել և կանխատեսումներ անել՝ ուսումնասիրելով տվյալներն ու վիճակագրությունը: Տրամադրված տվյալները ուսումնասիրելով՝ համակարգիչը կարող է բացահայտել և հանել օրինաչափությունները, ապա դրանց հիման վրա կանխատեսումներ անել։ Սպամ նամակների նույնականացումը, խոսքի ճանաչումը և երթևեկության կանխատեսումը մեքենայական ուսուցման իրական օգտագործման դեպքեր են:
Ավելի լավ օրինակի համար պատկերացրեք, որ մենք ուզում ենք համակարգչին սովորեցնել ճանաչել կատուներին լուսանկարներում: Դուք ցույց կտայիք կատուների բազմաթիվ նկարներ և կասեք. «Հեյ, համակարգիչ, սրանք կատուներ են»: Համակարգիչը նայում է նկարներին և սկսում է նախշեր նկատել, ինչպիսիք են սուր ականջները, բեղերը և մորթիները: Բավական օրինակներ տեսնելուց հետո այն կարող է ճանաչել կատվին նոր լուսանկարում, որը նախկինում չի տեսել:
Նման համակարգերից մեկը, որից մենք ամեն օր օգտվում ենք, էլփոստի սպամի զտիչներն են: Հետևյալ պատկերը ցույց է տալիս, թե ինչպես է դա արվում:
Ինչու՞ օգտագործել Python-ը:
Թեև Python ծրագրավորման լեզուն կառուցված չէ հատուկ ML-ի կամ Data Science-ի համար, այն համարվում է հիանալի ծրագրավորման լեզու ML-ի համար՝ իր հարմարվողականության պատճառով: Հարյուրավոր գրադարաններով, որոնք հասանելի են անվճար ներբեռնման համար, յուրաքանչյուրը կարող է հեշտությամբ կառուցել ML մոդելներ՝ օգտագործելով նախապես կառուցված գրադարան՝ առանց ամբողջական ընթացակարգը զրոյից ծրագրավորելու անհրաժեշտության:
TensorFlow-ն այդպիսի գրադարաններից մեկն է, որը կառուցվել է Google-ի կողմից մեքենայական ուսուցման և արհեստական ինտելեկտի համար: TensorFlow-ը հաճախ օգտագործվում է տվյալների գիտնականների, տվյալների ինժեներների և այլ մշակողների կողմից՝ հեշտությամբ մեքենայական ուսուցման մոդելներ ստեղծելու համար, քանի որ այն բաղկացած է մի շարք մեքենայական ուսուցման և AI ալգորիթմներից:
Այցելեք TensorFlow-ի պաշտոնական կայքը
Տեղադրում
Tensorflow-ը տեղադրելու համար ձեր տերմինալում գործարկեք հետևյալ հրամանը.
pip install tensorflowԵվ տեղադրել Pandas և Numpy,
pip install pandas numpyԽնդրում ենք ներբեռնել CSV ֆայլի նմուշը այս պահոցից՝ Github Repository - TensorFlow ML Model
Հասկանալով տվյալները
Տվյալների վերլուծության թիվ 1 կանոնը և այն ամենը, ինչ հիմնված է տվյալների վրա. նախ հասկացեք ձեր ունեցած տվյալները:
Այս դեպքում տվյալների հավաքածուն ունի երկու սյունակ՝ Տեքստ և զգացում: Թեև «տեքստ» սյունակում կան մի շարք արտահայտություններ, որոնք արված են ֆիլմերի, գրքերի և այլնի վերաբերյալ, «Զգացողություն» սյունակը ցույց է տալիս, թե արդյոք տեքստը դրական է, չեզոք կամ բացասական՝ օգտագործելով համապատասխանաբար 1, 2 և 0 համարները:
Տվյալների պատրաստում
Հաջորդ հիմնական կանոնը կրկնօրինակները մաքրելն է և ձեր ընտրանքային տվյալների զրոյական արժեքները հեռացնելն է: Բայց այս դեպքում, քանի որ տվյալ տվյալների հավաքածուն բավականին փոքր է և չի պարունակում կրկնօրինակներ կամ զրոյական արժեքներ, մենք կարող ենք բաց թողնել տվյալների մաքրման գործընթացը:
Մոդելի կառուցումը սկսելու համար մենք պետք է հավաքենք և պատրաստենք տվյալների բազան՝ տրամադրությունների վերլուծության մոդելը վարժեցնելու համար: Պանդաները՝ տվյալների վերլուծության և մանիպուլյացիայի հայտնի գրադարանը, կարող են օգտագործվել այս առաջադրանքի համար:
import pandas as pd # Load data from CSV data = pd.read_csv('sentiment.csv') # Change the path of downloaded CSV File accordingly # Text data and labels texts = data['text'].tolist() labels = data['sentiment'].values Վերոնշյալ կոդը փոխակերպում է CSV ֆայլը տվյալների շրջանակի՝ օգտագործելով pandas.read_csv() ֆունկցիան։ Այնուհետև այն վերագրում է «սենտիմենտ» սյունակի արժեքները Python ցուցակին՝ օգտագործելով tolist() ֆունկցիան և ստեղծում է Numpy զանգված՝ արժեքներով:
Ինչու՞ օգտագործել Numpy զանգված:
Ինչպես արդեն գիտեք, Numpy-ն հիմնականում ստեղծվել է տվյալների մանիպուլյացիայի համար: Numpy զանգվածները արդյունավետ կերպով մշակում են թվային պիտակները մեքենայական ուսուցման առաջադրանքների համար, ինչը ճկունություն է տալիս տվյալների կազմակերպմանը: Ահա թե ինչու մենք օգտագործում ենք Numpy այս դեպքում:
Տեքստի մշակում
Նմուշի տվյալները պատրաստելուց հետո մենք պետք է վերամշակենք տեքստը, որը ներառում է Tokenization:
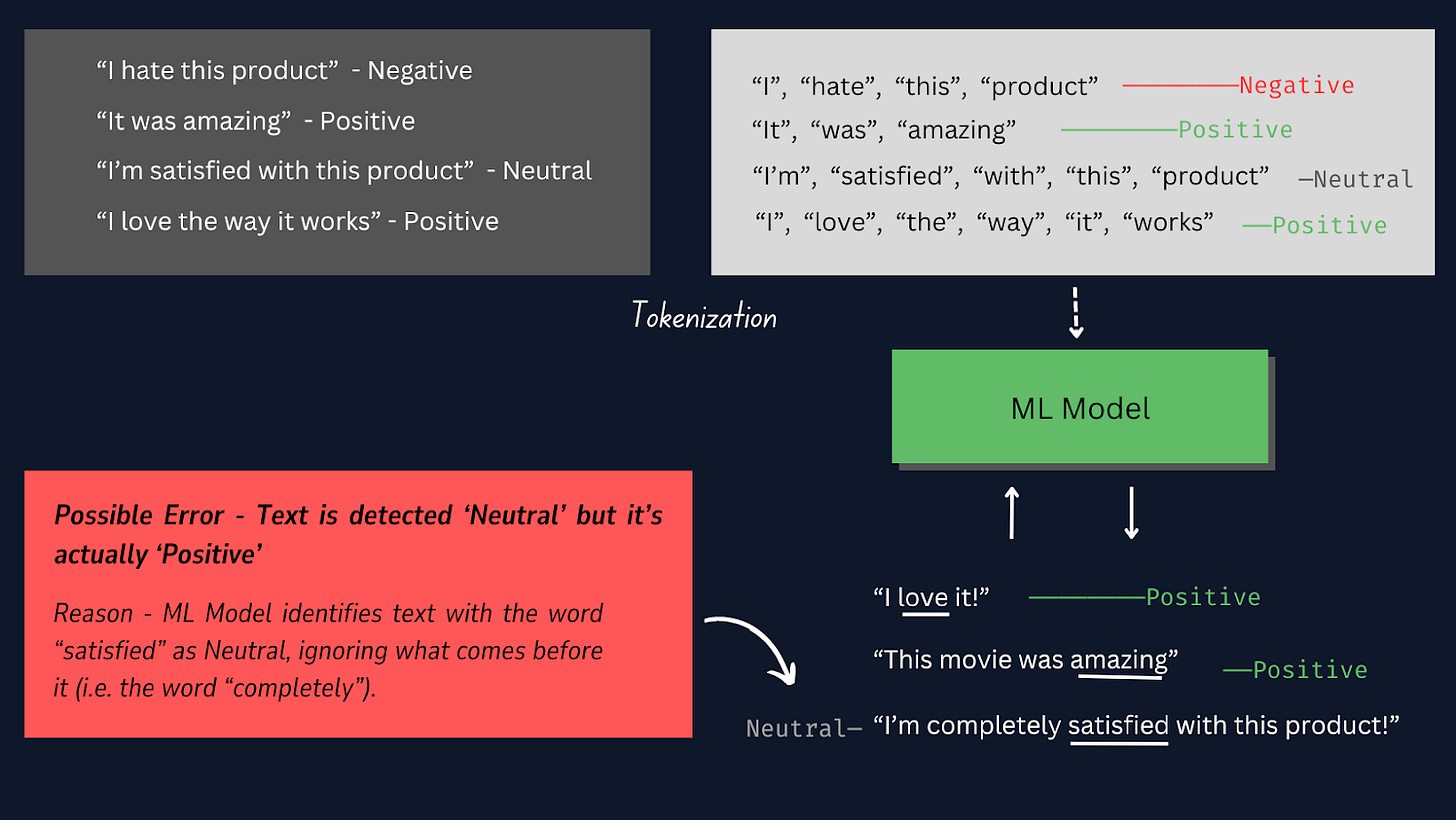
Tokenization-ը տեքստի յուրաքանչյուր նմուշ առանձին բառերի կամ նշանների բաժանելու գործընթացն է, որպեսզի մենք կարողանանք չմշակված տեքստի տվյալները վերածել մոդելի կողմից մշակվող ձևաչափի , ինչը թույլ կտա նրան հասկանալ և սովորել տեքստի նմուշների առանձին բառերը: .
Տե՛ս ստորև բերված պատկերը՝ իմանալու համար, թե ինչպես է աշխատում նշանավորումը:
Այս նախագծում ավելի լավ է օգտագործել ձեռքով նշանավորումը այլ նախապես կառուցված թոքենիզատորների փոխարեն, քանի որ այն ապահովում է մեզ ավելի մեծ վերահսկողություն նշանավորման գործընթացի նկատմամբ, ապահովում է տվյալների հատուկ ձևաչափերի հետ համատեղելիություն և թույլ է տալիս համապատասխանեցված նախնական մշակման քայլերը:
Նշում. Manual Tokenization-ում մենք գրում ենք կոդ՝ տեքստը բառերի բաժանելու համար, ինչը շատ հարմարեցված է՝ ըստ նախագծի կարիքների: Այնուամենայնիվ, այլ մեթոդներ, ինչպիսիք են TensorFlow Keras Tokenizer-ի օգտագործումը, գալիս են տեքստի ավտոմատ բաժանման պատրաստի գործիքներով և գործառույթներով, որն ավելի հեշտ է իրականացնել, բայց ավելի քիչ հարմարեցված:
Ստորև բերված է կոդի հատվածը, որը մենք կարող ենք օգտագործել նմուշի տվյալների խորհրդանշականացման համար:
word_index = {} sequences = [] for text in texts: words = text.lower().split() sequence = [] for word in words: if word not in word_index: word_index[word] = len(word_index) + 1 sequence.append(word_index[word]) sequences.append(sequence)Վերոնշյալ օրենսգրքում՝
-
word_index. Դատարկ բառարան, որը ստեղծվել է տվյալների շտեմարանում յուրաքանչյուր եզակի բառ՝ դրա արժեքի հետ միասին պահելու համար: -
sequences. դատարկ ցուցակ, որը պահպանում է բառերի թվային ներկայացման հաջորդականությունները տեքստի յուրաքանչյուր նմուշի համար: -
for text in texts. պտտվում է յուրաքանչյուր տեքստի նմուշի միջով «տեքստեր» ցանկում (ավելի վաղ ստեղծված): -
words = text.lower().split(): Փոխակերպում է յուրաքանչյուր տեքստի նմուշ փոքրատառի և այն բաժանում առանձին բառերի` հիմնվելով բացատների վրա: -
for word in words. Ներդրված հանգույց, որը կրկնվում է «բառերի» ցանկի յուրաքանչյուր բառի վրա, որը պարունակում է ընթացիկ տեքստի նմուշների խորհրդանշական բառերը: -
if word not in word_index. Եթե բառը ներկայումս չկա word_index բառարանում, այն ավելացվում է դրան եզակի ինդեքսով, որը ստացվում է բառարանի ընթացիկ երկարությանը 1 ավելացնելով: -
sequence. append (word_index[word]): Ընթացիկ բառի ինդեքսը որոշելուց հետո այն կցվում է «հաջորդական» ցանկին: Սա փոխակերպում է տեքստի նմուշի յուրաքանչյուր բառ իր համապատասխան ինդեքսին՝ հիմնված «word_index» բառարանի վրա: -
sequence.append(sequence). Այն բանից հետո, երբ տեքստի նմուշի բոլոր բառերը փոխարկվեն թվային ինդեքսների և պահվեն «sequence» ցանկում, այս ցանկը կցվում է «sequences» ցանկին:
Ամփոփելով, վերը նշված կոդը տեքստային տվյալները վերածում է յուրաքանչյուր բառի թվային ներկայացման՝ հիմնվելով բառարանի word_index վրա, որը բառերը քարտեզագրում է եզակի ինդեքսների: Այն ստեղծում է թվային ներկայացումների հաջորդականություն յուրաքանչյուր տեքստի նմուշի համար, որը կարող է օգտագործվել որպես մոդելի մուտքային տվյալ:
Մոդելային ճարտարապետություն
Որոշակի մոդելի ճարտարապետությունը շերտերի, բաղադրիչների և կապերի դասավորությունն է, որը որոշում է, թե ինչպես են տվյալների հոսքը դրա միջով : Մոդելի ճարտարապետությունը էական ազդեցություն ունի մոդելի ուսուցման արագության, կատարողականի և ընդհանրացման կարողության վրա:
Մուտքային տվյալները մշակելուց հետո մենք կարող ենք սահմանել մոդելի ճարտարապետությունը, ինչպես հետևյալ օրինակում.
model = tf.keras.Sequential([ tf.keras.layers.Embedding(len(word_index) + 1, 16, input_length=max_length), tf.keras.layers.LSTM(64), tf.keras.layers.Dense(3, activation='softmax') ])
Վերոնշյալ կոդում մենք օգտագործում ենք TensorFlow Keras-ը, որը բարձր մակարդակի նեյրոնային ցանցերի API է, որը կառուցված է Deep Learning մոդելների արագ փորձարկումների և նախատիպերի համար՝ պարզեցնելով մեքենայական ուսուցման մոդելների կառուցման և կազմման գործընթացը:
-
tf. keras.Sequential()՝ հաջորդական մոդելի սահմանում, որը շերտերի գծային փաթեթ է: Տվյալները հոսում են առաջին շերտից մինչև վերջին՝ ըստ հերթականության։ -
tf.keras.layers.Embedding(len(word_index) + 1, 16, input_length=max_length): Այս շերտը օգտագործվում է բառերի ներկառուցման համար, որը բառերը փոխակերպում է ֆիքսված չափի խիտ վեկտորների: Len(word_index) + 1-ը նշում է բառապաշարի չափը, 16-ը ներդրման չափականությունն է, իսկ input_length=max_length սահմանում է մուտքագրման երկարությունը յուրաքանչյուր հաջորդականության համար: -
tf.keras.layers.LSTM(64): Այս շերտը երկար կարճաժամկետ հիշողության (LSTM) շերտ է, որը կրկնվող նեյրոնային ցանցի (RNN) տեսակ է: Այն մշակում է բառերի ներկառուցման հաջորդականությունը և կարող է «հիշել» տվյալների մեջ կարևոր օրինաչափությունները կամ կախվածությունները: Այն ունի 64 միավոր, որոնք որոշում են ելքային տարածության չափսերը։ -
tf.keras.layers.Dense(3, activation='softmax'): Սա խիտ կապված շերտ է 3 միավորով և softmax ակտիվացման ֆունկցիայով: Դա մոդելի ելքային շերտն է, որն արտադրում է հավանականության բաշխում երեք հնարավոր դասերի վրա (ենթադրելով բազմադաս դասակարգման խնդիր):
Կազմում
TensorFlow-ով մեքենայական ուսուցման մեջ կոմպիլյացիան վերաբերում է ուսուցման համար մոդելի կազմաձևման գործընթացին՝ նշելով երեք հիմնական բաղադրիչ ՝ կորստի ֆունկցիա, օպտիմիզատոր և չափումներ:
Կորուստի գործառույթ . Չափում է մոդելի կանխատեսումների և իրական թիրախների միջև եղած սխալը՝ օգնելով ուղղորդել մոդելի ճշգրտումները:
Օպտիմիզատոր . Կարգավորում է մոդելի պարամետրերը՝ նվազագույնի հասցնելու կորստի գործառույթը՝ հնարավորություն տալով արդյունավետ ուսուցում:
Չափումներ . Ապահովում է կատարողականի գնահատում կորստից դուրս, ինչպիսիք են ճշգրտությունը կամ ճշգրտությունը, որն օգնում է մոդելի գնահատմանը:
Ստորև բերված կոդը կարող է օգտագործվել զգացմունքների վերլուծության մոդելը կազմելու համար.
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])Այստեղ,
loss='sparse_categorical_crossentropy': Կորստի ֆունկցիան սովորաբար օգտագործվում է դասակարգման առաջադրանքների համար՝ անկախ նրանից, թե թիրախային պիտակները ամբողջ թվեր են, և մոդելի արդյունքը հավանականության բաշխում է բազմաթիվ դասերի վրա: Այն չափում է իրական պիտակների և կանխատեսումների միջև եղած տարբերությունը ՝ նպատակ ունենալով նվազագույնի հասցնել այն մարզումների ընթացքում:optimizer='adam': Ադամը օպտիմալացման ալգորիթմ է, որը դինամիկ կերպով հարմարեցնում է ուսուցման արագությունը վերապատրաստման ընթացքում: Այն լայնորեն կիրառվում է պրակտիկայում՝ իր արդյունավետության, կայունության և արդյունավետության պատճառով, երբ համեմատվում է այլ օպտիմիզատորների հետ:metrics = ['accuracy']: Ճշգրտությունը սովորական չափիչ է, որը հաճախ օգտագործվում է դասակարգման մոդելները գնահատելու համար: Այն ապահովում է առաջադրանքի վրա մոդելի ընդհանուր կատարողականի պարզ չափում, քանի որ այն նմուշների տոկոսը, որոնց համար մոդելի կանխատեսումները համապատասխանում են իրական պիտակներին:
Մոդելի ուսուցում
Այժմ, երբ մուտքային տվյալները մշակված են և պատրաստ են, և մոդելի ճարտարապետությունը նույնպես սահմանված է, մենք կարող ենք վարժեցնել մոդելը՝ օգտագործելով model.fit() մեթոդը:
model.fit(padded_sequences, labels, epochs=15, verbose=1)padded_sequences. Մոդելի վերապատրաստման մուտքային տվյալներ, որոնք բաղկացած են նույն չափերի հաջորդականություններից (լիցքավորումը կքննարկվի ավելի ուշ ձեռնարկում):labels. թիրախային պիտակներ, որոնք համապատասխանում են մուտքային տվյալներին (այսինքն՝ տրամադրությունների կատեգորիաները, որոնք վերագրված են յուրաքանչյուր տեքստի նմուշին)epochs=15. Դարաշրջանը վերապատրաստման գործընթացի ընթացքում մեկ ամբողջական անցում է վերապատրաստման ամբողջական տվյալների բազայի միջով: Համապատասխանաբար, այս ծրագրում մոդելը վերապատրաստման ընթացքում 15 անգամ կրկնում է ամբողջական տվյալների վրա:
Երբ դարաշրջանների թիվն ավելանում է, դա պոտենցիալ կբարելավի կատարումը, քանի որ այն ավելի բարդ օրինաչափություններ է սովորում տվյալների նմուշների միջոցով: Այնուամենայնիվ, եթե օգտագործվում են չափազանց շատ դարաշրջաններ, մոդելը կարող է մտապահել վերապատրաստման տվյալները, ինչը հանգեցնում է նոր տվյալների վատ ընդհանրացման (որը կոչվում է «գերհամապատասխանում»): Դասընթացների համար ծախսվող ժամանակը նույնպես կավելանա դարաշրջանների աճի հետ և հակառակը:
verbose=1. սա պարամետր է՝ վերահսկելու համար, թե որքան արդյունք է արտադրում մոդելի հարմարեցման մեթոդը մարզվելիս: 1 արժեքը նշանակում է, որ առաջընթացի գծերը կցուցադրվեն վահանակում, քանի որ մոդելը գնում է, 0-ը նշանակում է ելք չկա, իսկ 2-ը նշանակում է մեկ տող մեկ դարաշրջանում: Քանի որ լավ կլինի տեսնել ճշգրտության և կորստի արժեքները և յուրաքանչյուր դարաշրջանի համար պահանջվող ժամանակը, մենք այն կդնենք 1-ի:
Կանխատեսումներ անելը
Մոդելի կազմումից և վերապատրաստումից հետո այն վերջապես կարող է կանխատեսումներ անել՝ հիմնվելով մեր նմուշի տվյալների վրա՝ պարզապես օգտագործելով predict() ֆունկցիան։ Այնուամենայնիվ, մենք պետք է մուտքագրենք մուտքային տվյալներ մոդելը փորձարկելու և ելք ստանալու համար: Դա անելու համար մենք պետք է մուտքագրենք որոշ տեքստային հայտարարություններ և այնուհետև խնդրենք մոդելին կանխատեսել մուտքային տվյալների տրամադրությունը:
test_texts = ["The price was too high for the quality", "The interface is user-friendly", "I'm satisfied"] test_sequences = [] for text in test_texts: words = text.lower().split() sequence = [] for word in words: if word in word_index: sequence.append(word_index[word]) test_sequences.append(sequence) Այստեղ test_texts պահում է որոշ մուտքային տվյալներ, մինչդեռ test_sequences ցուցակն օգտագործվում է նիշացված թեստային տվյալները պահելու համար, որոնք փոքրատառերի վերածվելուց հետո բաժանված բառեր են: Այնուամենայնիվ, test_sequences չի կարողանա գործել որպես մոդելի մուտքային տվյալ:
Պատճառն այն է, որ շատ խորը ուսուցման շրջանակներ, ներառյալ Tensorflow-ը, սովորաբար պահանջում են մուտքային տվյալների միատեսակ չափում (ինչը նշանակում է, որ յուրաքանչյուր հաջորդականության երկարությունը պետք է հավասար լինի), տվյալների խմբաքանակն արդյունավետ մշակելու համար: Դրան հասնելու համար դուք կարող եք օգտագործել այնպիսի տեխնիկա, ինչպիսին է padding-ը, որտեղ հաջորդականությունները երկարացվում են տվյալների հավաքածուի ամենաերկար հաջորդականությունների երկարությանը համապատասխանելու համար՝ օգտագործելով հատուկ նշան, ինչպիսին է # կամ 0 (0, այս օրինակում):
import numpy as np padded_test_sequences = [] for sequence in test_sequences: padded_sequence = sequence[:max_length] + [0] * (max_length - len(sequence)) padded_test_sequences.append(padded_sequence) # Convert to numpy array padded_test_sequences = np.array(padded_test_sequences)Տվյալ օրենսգրքում՝
-
padded_test_sequences. դատարկ ցուցակ՝ լիցքավորված հաջորդականությունները պահելու համար, որոնք կօգտագործվեն մոդելը փորձարկելու համար: -
for sequence in sequences՝ «sequences» ցանկի յուրաքանչյուր հաջորդականության միջով: -
padded_sequence. Ստեղծում է նոր լիցքավորված հաջորդականություն յուրաքանչյուր հաջորդականության համար՝ կտրելով սկզբնական հաջորդականությունը առաջին max_length տարրերին՝ հետևողականություն ապահովելու համար: Այնուհետև մենք հաջորդականությունը լրացնում ենք զրոներով, որպեսզի համապատասխանի max_length-ին, եթե այն ավելի կարճ է, արդյունավետորեն բոլոր հաջորդականությունները դարձնելով նույն երկարությունը: -
padded_test_sequences.append(): Ավելացրեք լիցքավորված հաջորդականություն ցուցակին, որը կօգտագործվի փորձարկման համար: -
padded_sequences = np.array().
Այժմ, քանի որ մուտքային տվյալները պատրաստ են օգտագործման, մոդելը վերջապես կարող է կանխատեսել մուտքային տեքստերի տրամադրությունը:
predictions = model.predict(padded_test_sequences) # Print predicted sentiments for i, text in enumerate(test_texts): print(f"Text: {text}, Predicted Sentiment: {np.argmax(predictions[i])}") Վերոնշյալ կոդում model.predict() մեթոդը ստեղծում է կանխատեսումներ յուրաքանչյուր փորձարկման հաջորդականության համար՝ արտադրելով կանխատեսված հավանականությունների զանգված յուրաքանչյուր տրամադրության կատեգորիայի համար։ Այնուհետև այն կրկնվում է յուրաքանչյուր test_texts տարրի միջոցով և np.argmax(predictions[i]) վերադարձնում է ամենամեծ հավանականության ինդեքսը կանխատեսված հավանականությունների զանգվածում i-րդ թեստային նմուշի համար: Այս ցուցանիշը համապատասխանում է կանխատեսված տրամադրությունների կատեգորիային, որն ունի ամենաբարձր կանխատեսված հավանականությունը յուրաքանչյուր փորձանմուշի համար, ինչը նշանակում է, որ արված լավագույն կանխատեսումը արդյունահանվում և ցուցադրվում է որպես հիմնական արդյունք:
Հատուկ նշումներ *:* np.argmax() ը NumPy ֆունկցիա է, որը գտնում է զանգվածի առավելագույն արժեքի ինդեքսը: Այս համատեքստում, np.argmax(predictions[i]) օգնում է որոշել տրամադրությունների կատեգորիան ամենաբարձր կանխատեսված հավանականությամբ յուրաքանչյուր փորձարկման նմուշի համար:
Ծրագիրն այժմ պատրաստ է գործարկման: Մոդելը կազմելուց և վարժեցնելուց հետո մեքենայական ուսուցման մոդելը կտպագրի իր կանխատեսումները մուտքային տվյալների համար:
Մոդելի արդյունքներում մենք կարող ենք տեսնել արժեքները որպես «Ճշգրտություն» և «Կորուստ» յուրաքանչյուր դարաշրջանի համար: Ինչպես նշվեց նախկինում, Ճշգրտությունը ճիշտ կանխատեսումների տոկոսն է ընդհանուր կանխատեսումներից: Որքան բարձր ճշգրտությունը ավելի լավ է: Եթե ճշգրտությունը 1.0 է, ինչը նշանակում է 100%, նշանակում է, որ մոդելը բոլոր դեպքերում ճիշտ կանխատեսումներ է արել։ Նմանապես, 0,5-ը նշանակում է, որ մոդելը ճիշտ կանխատեսումներ է արել կես անգամ, 0,25-ը նշանակում է ճիշտ կանխատեսում ժամանակի եռամսյակում և այլն:
Մյուս կողմից, կորուստը ցույց է տալիս, թե որքան վատ են մոդելի կանխատեսումները համապատասխանում իրական արժեքներին: Կորստի փոքր արժեքը նշանակում է ավելի լավ մոդել՝ ավելի քիչ թվով սխալներով, իսկ 0 արժեքը կորստի կատարյալ արժեք է, քանի որ դա նշանակում է, որ սխալներ չեն արվել:
Այնուամենայնիվ, մենք չենք կարող որոշել մոդելի ընդհանուր ճշգրտությունը և կորուստը յուրաքանչյուր դարաշրջանի համար ցուցադրված վերը նշված տվյալներով: Դա անելու համար մենք կարող ենք գնահատել մոդելը, օգտագործելով գնահատում() մեթոդը և տպել դրա ճշգրտությունը և կորուստը:
evaluation = model.evaluate(padded_sequences, labels, verbose=0) # Extract loss and accuracy loss = evaluation[0] accuracy = evaluation[1] # Print loss and accuracy print("Loss:", loss) print("Accuracy:", accuracy)Արդյունք:
Loss: 0.6483516097068787 Accuracy: 0.7058823704719543Համապատասխանաբար, այս մոդելում Loss-ի արժեքը 0,6483 է, ինչը նշանակում է, որ մոդելը թույլ է տվել որոշ սխալներ: Մոդելի ճշգրտությունը կազմում է մոտ 70%, ինչը նշանակում է, որ մոդելի կողմից արված կանխատեսումները ճիշտ են ժամանակի կեսից ավելին: Ընդհանուր առմամբ, այս մոդելը կարելի է համարել «մի փոքր լավ» մոդել. Այնուամենայնիվ, խնդրում ենք նկատի ունենալ, որ «լավ» կորստի և ճշտության արժեքները մեծապես կախված են մոդելի տեսակից, տվյալների բազայի չափից և որոշակի Մեքենայի ուսուցման մոդելի նպատակից:
Եվ այո, մենք կարող ենք և պետք է բարելավենք մոդելի վերը նշված չափումները՝ ճշգրտելով գործընթացները և ավելի լավ նմուշային տվյալների հավաքածուներ: Այնուամենայնիվ, հանուն այս ձեռնարկի, եկեք կանգ առնենք այստեղից: Եթե ցանկանում եք այս ձեռնարկի երկրորդ մասը, խնդրում եմ տեղեկացրեք ինձ:
Ամփոփում
Այս ձեռնարկում մենք կառուցեցինք TensorFlow մեքենայական ուսուցման մոդել՝ որոշակի տեքստի տրամադրությունը կանխատեսելու ունակությամբ՝ վերլուծելով նմուշի տվյալների հավաքածուն:
Ամբողջական կոդը և CSV ֆայլի նմուշը կարելի է ներբեռնել և տեսնել GitHub պահեստում - GitHub - Buzzpy/Tensorflow-ML-Model
L O A D I N G
. . . comments & more!
. . . comments & more!



